ChatGPT相关
1.相关文献总结
(1)多模态预训练:
综述:
Vision-Language Pre-training: Basics, Recent Advances, and Future Trends
多模态框架(包含:ALBEF, BLIP, BLIP2等): https://github.com/salesforce/LAVIS
博文推荐:https://zhuanlan.zhihu.com/p/616351346
(2)数据集:
图文:
MMDialog: A Large-scale Multi-turn Dialogue Dataset Towards Multi-modal Open-domain Conversation (MMDialog) [✅]
视频
TikTalk: A Multi-Modal Dialogue Dataset for Real-World Chitchat (TikTalk) [✅]
(3)纯文本ChatGPT:
大模型
Improving Language Understanding By Genertative Pre-trying (GPT-1) [✅]
Language Models are Unsupervised Multitask Learners (GPT-2) [✅]
Language Models are Few-Shot Learners (GPT-3) [✅]
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
Instruction tuning
Finetuned Language Models Are Zero-Shot Learners (FLAN) [✅]
Multitask Prompted Training Enables Zero-Shot Task Generalization (T0) [✅]
Scaling Instruction-Finetuned Language Models (Flan-PaLM) [✅]
SELF-INSTRUCT: Aligning Language Model with Self Generated Instructions (SELF-INSTRUCT) [✅]
大模型+对话
Training language models to follow instructions with human feedback (InstructGPT) [✅]
Baize: An Open-Source Chat Model with Parameter-Effificient Tuning on Self-Chat Data (Baize) [✅]
(4)多模态ChatGPT:
Flamingo: a Visual Language Model for Few-Shot Learning (Flamingo) [✅]
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models (Blip-2) [✅]
GIT: A Generative Image-to-text Transformer for Vision and Language
MultiInstruct: Improving Multi-Modal Zero-Shot Learning via Instruction Tuning
Prompting Large Language Models with Answer Heuristics for Knowledge-based Visual Question Answering (Prophet) [✅]
Language Is Not All You Need: Aligning Perception with Language Models (KOSMOS-1) [✅]
Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models (Visual ChatGPT) [✅]
MM-REACT: Prompting ChatGPT for Multimodal Reasoning and Action (MM-REACT) [✅]
REVIVE: Regional Visual Representation Matters in Knowledge-Based Visual Question Answering (REVIVE) [✅]
An Empirical Study of GPT-3 for Few-Shot Knowledge-Based VQA (PICa) [✅]
MULTIINSTRUCT: Improving Multi-Modal Zero-Shot Learning via Instruction Tuning (MultiInstruct) [✅]
MiniGPT-4:Enhancing Vision-Language Understanding with Advanced Large Language Models (MiniGPT-4) [✅]
Visual Instruction Tuning (LLaVa) [✅]
(5)评测:
《txt2img的评测》TIFA: Accurate and Interpretable Text-to-Image Faithfulness Evaluation with Question Answering (TIFA) [✅]
2.文献阅读笔记
2.1.Prophet
本文指出早期用外部知识库来引导回答图片问题KB-VQA任务,外部知识的一些无关信息可能会造成误导。本文提出了用VQA模型生成一系列针对图片的指导信息,然后用这些构造成prompt去指导文本GPT生成答案。
Introduction
这部分指出传统的KB-VQA任务会存在两个问题:
(1)所需的知识可能无法从kb中成功检索
(2)即使检索到所需的知识,也不可避免地引入大量无关的知识
但是也会有像PICa这类模型用caption model去获取图片的caption,然后用得到的caption和一些固定格式的promt输入GPT-3去得到答案。
本文说上述两种方法都有缺陷:
(1)PICa的方法用的caption model可能并不会得到关于问题的信息:
eg.
![]()
这张图中caption并不会注意到椰子树,如果用这个caption组合,然后问:图中的树会长什么果子?这样会有问题。
(2)在给到一个任务给GPT-3时候,它依赖上下文,所以上下文例子选择至关重要。

Prophet的上下文策略文中叫做answer heuristics,有两种形式:1.answer candidates. 2.answer-aware examples.
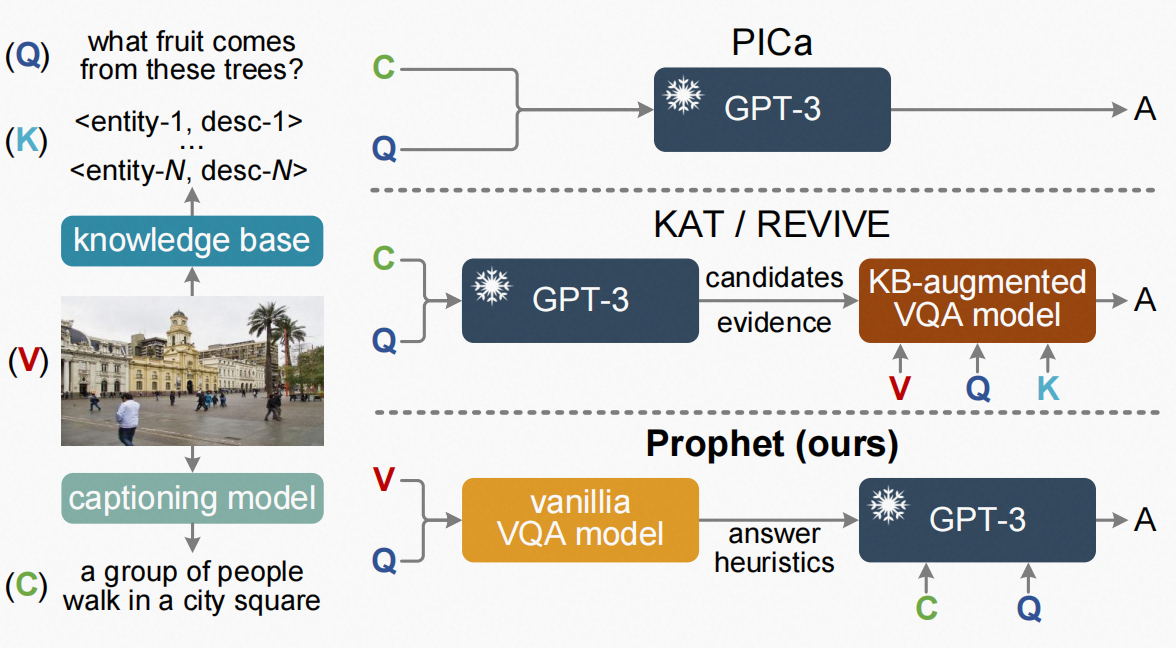
Framework
整个模型是两阶段
(1)第一阶段:训练一个VQA模型获得两种形式的answer heuristics
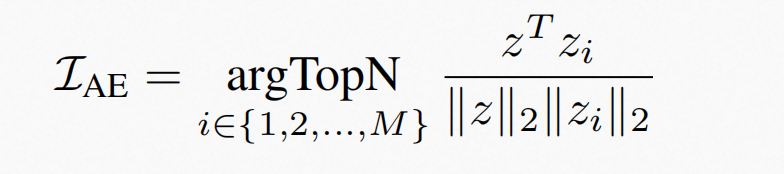
其中answer-aware examples的选择是通过上述式子计算出融合模态表征同其他样本融合表征的相似度,因为融合后的表征相似度高,他们所在的潜在答案空间重叠就高,然后选取相似度最高的N个做为上下文answer-aware examples。
(2)第二阶段:在启发式增强的提示阶段,answer heuristics和caption被集成到一个格式化的提示中,以指导GPT-3预测一个答案
整个模型如下:
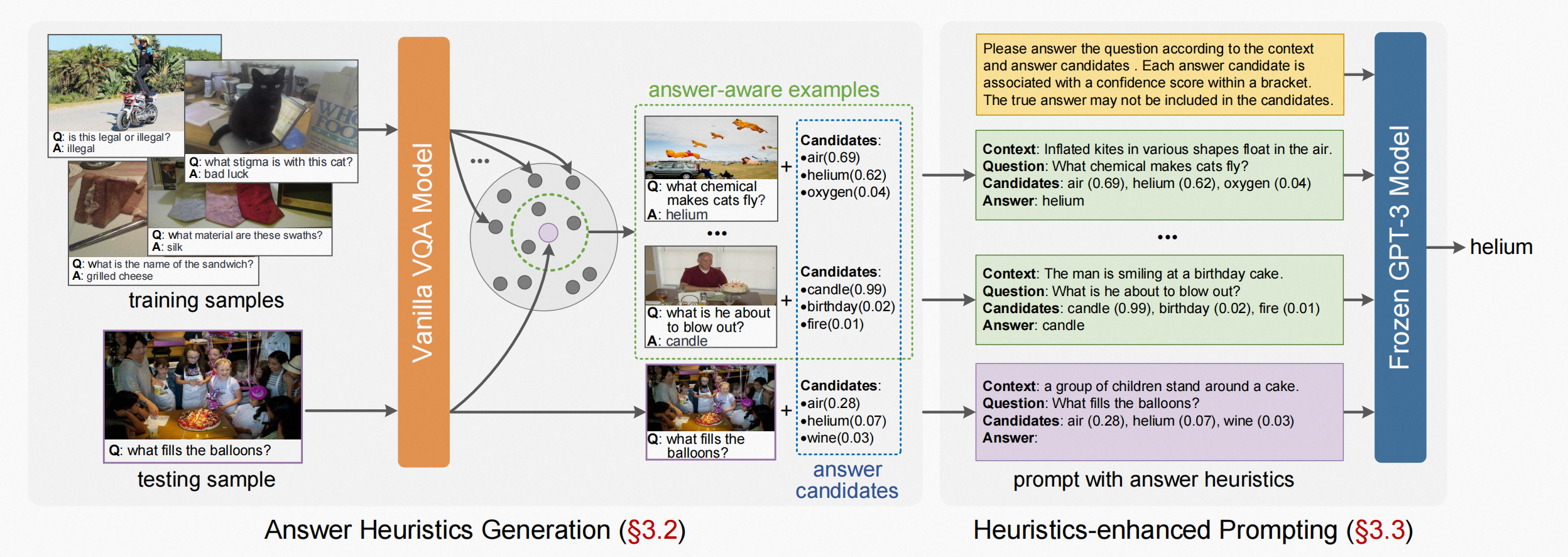
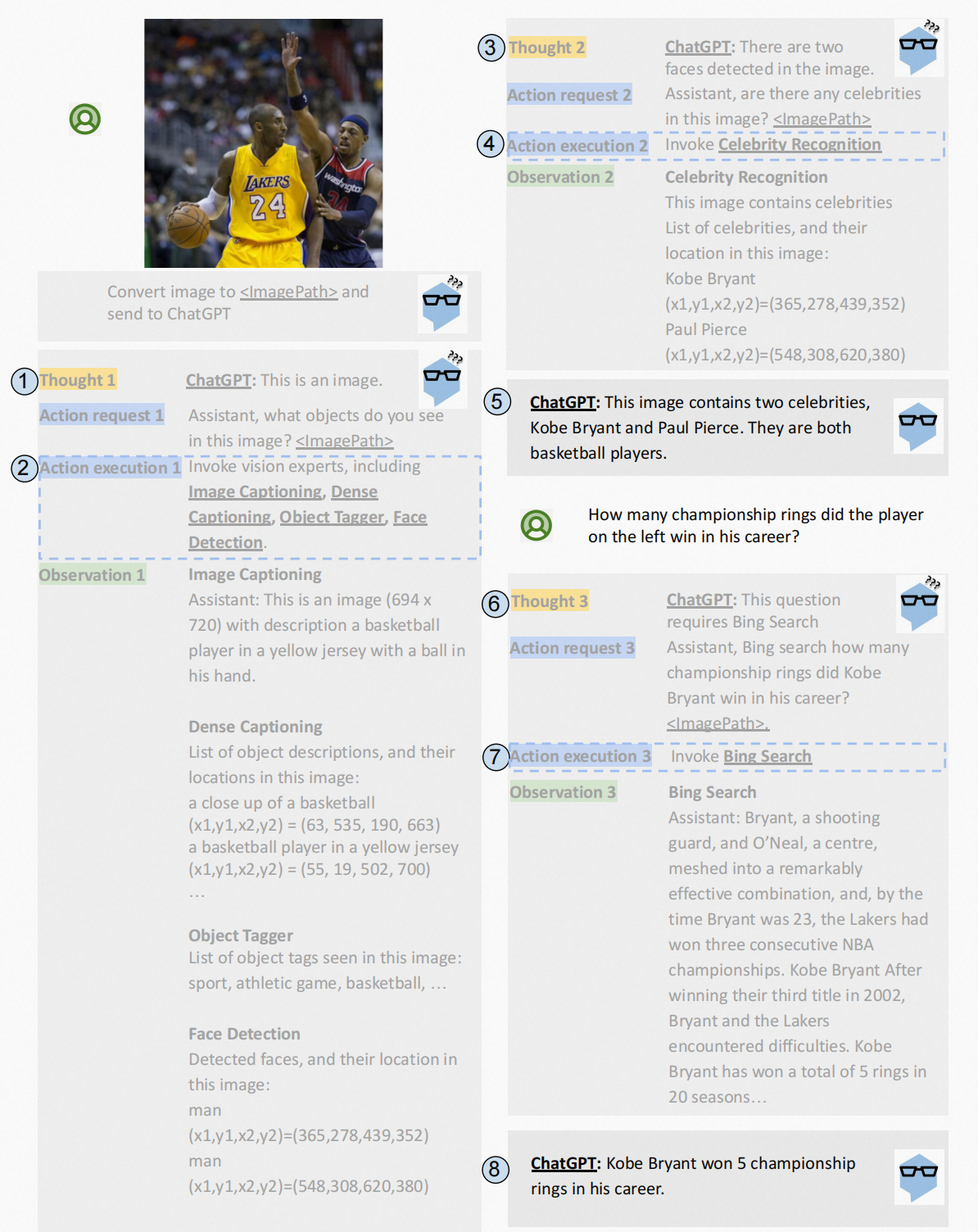
2.2.MM-React
MM-React的prompt设计利于LLM接受多模态信息。本文注重于利用单独的视觉模型和LLM分离的让LLM理解图像。
Introduction
这部分指出:
很多工作是多模态融合,类似于Flamingo和PaLM-E等,这种模型效果好但计算贵。
MM-React输入图片等非文本模态的数据的使用直接采用PATH,相当于告诉语言模型这有个占位符。
Framework
不同的视觉模型提供不同的信息,例如:目标检测,OCR,实体命名模型。MM-React的目的是根据用户以自然语言查询提供的需求来自动化这个过程。
整个框架如下:
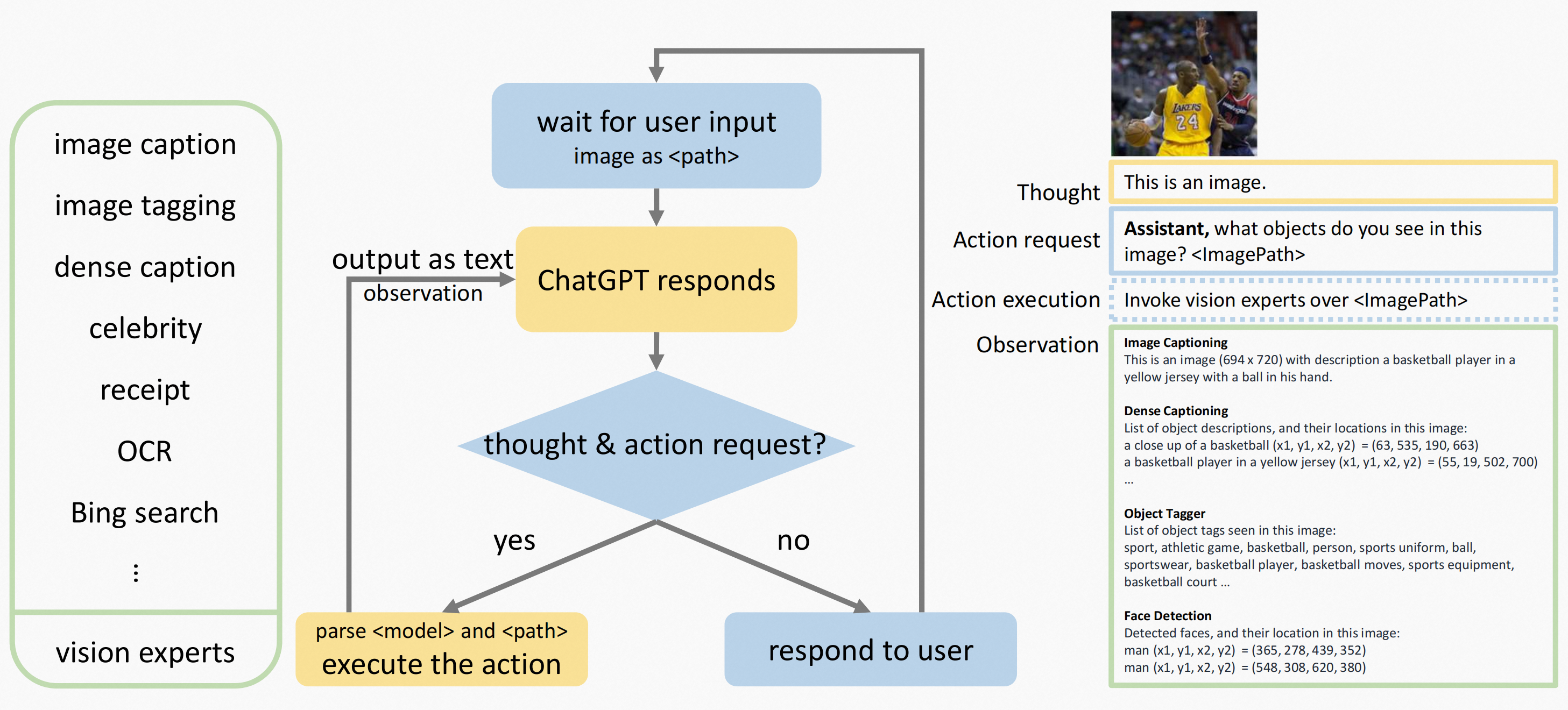
gpt在系统中的一个思考流程:
2.3.Self-Instruct
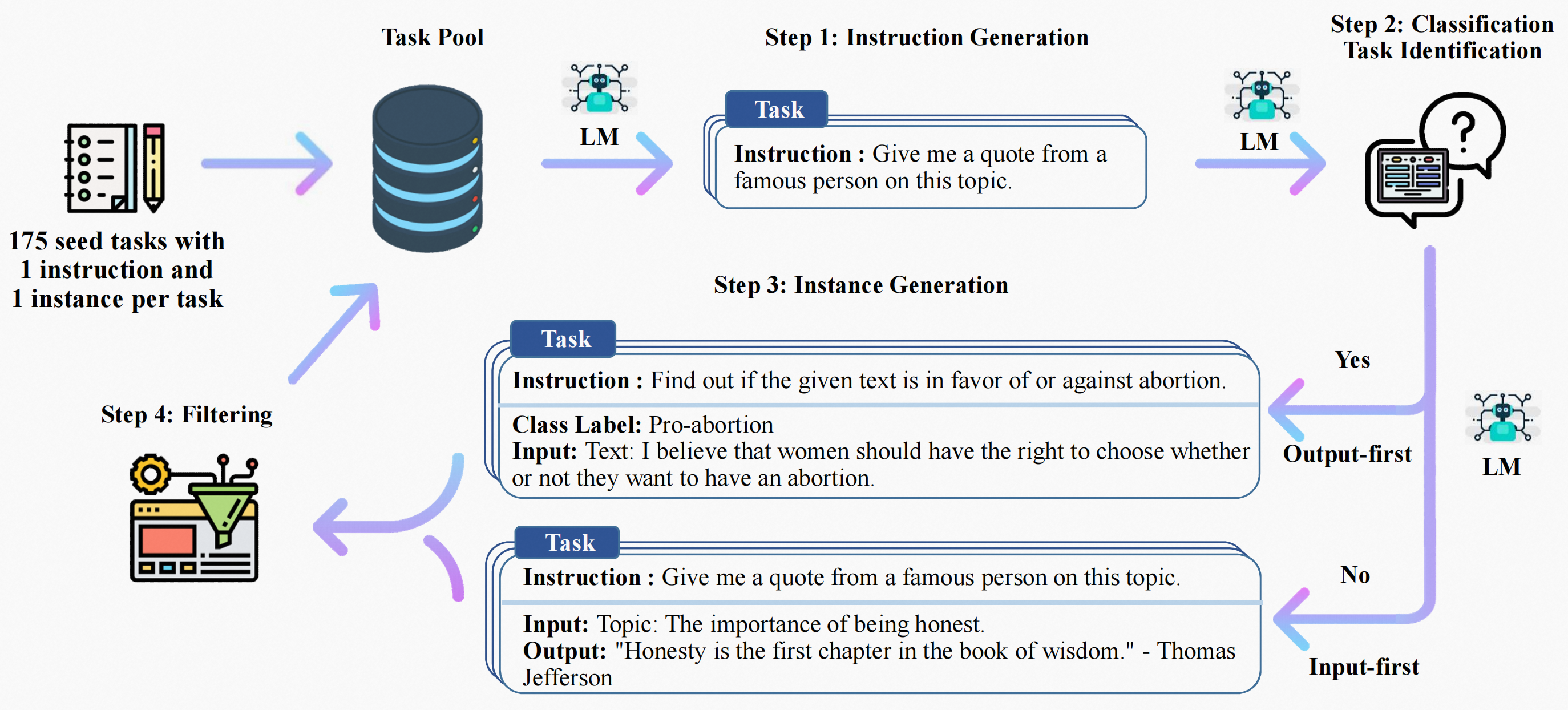
现在的instruction-tuned llm能力不错,但是人工标注费时费力且质量多样性不高,所以本文提出self-instruct,让模型自己指导自己遵循指令。
Introduction
人工撰写instruct数据集缺乏多样性,偏向于热门的NLP任务,没有涵盖真正的各种任务和不同的方式来描述它们。考虑到这些限制,要继续提高指令调优模型的质量,就需要进行开发替代方法。
self-instruct的整个流程是一个自我提高算法,从一个人工的instruction小数据集开始,指导自己整个生成过程。在第一阶段中,将提示模型为新任务生成指令。这一步利用现有的指令集合来创建更广泛的指令来定义( 通常是新的)任务。给定新生成的指令集,该框架还为它们创建输入-输出实例,稍后可以用于监督指令调优。最后,用各种措施来删除低质量和重复的指令。这个过程可以重复进行许多交互,直到完成大量的任务。
Framework
Limitation
(1) Tail Phenomena
(2) Dependence on large models
(3) Reinforcing LM biases
2.4.REVIVE
本文提出现有的很多kbVQA方法存在两个问题(1)关注整个视觉,或者滑动窗口检索,忽视了region对于vqa任务的重要性(2)没有很好利用视觉模态特征。本文提出的REVIVE说明了这些region信息的重要性,主要利用显示的检索信息和region信息。
Introduction
现有工作聚焦于整合外部knowledge,本文侧重于视觉一侧聚焦region对于vqa任务的重要性。
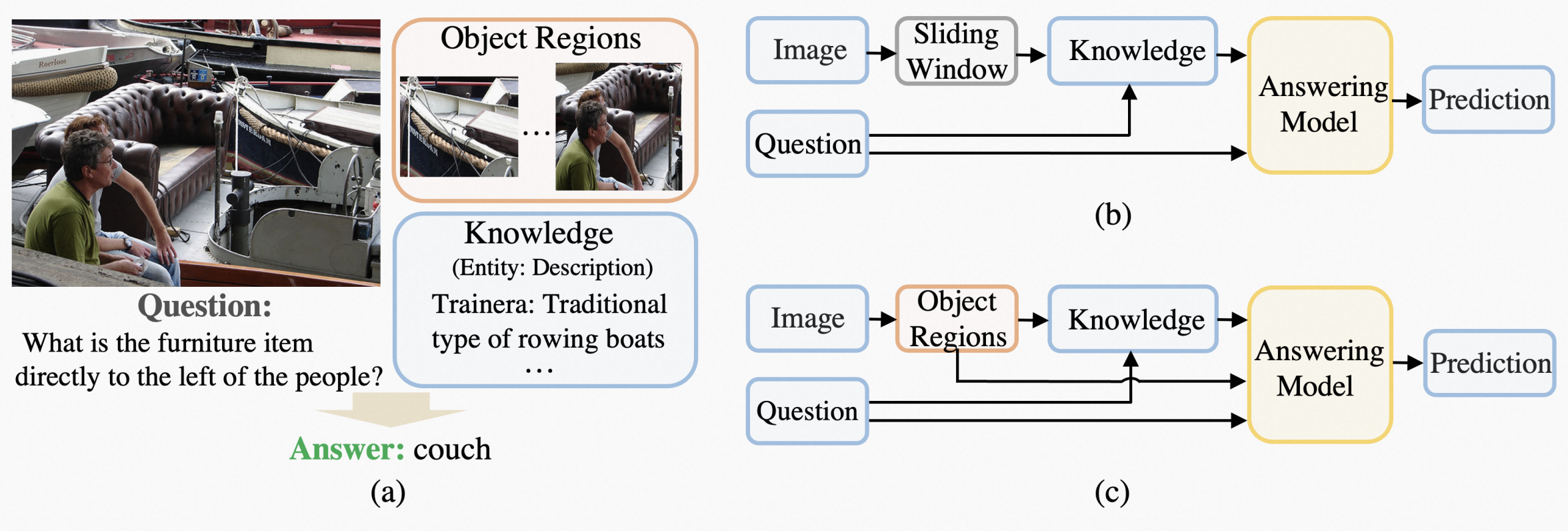
Framework
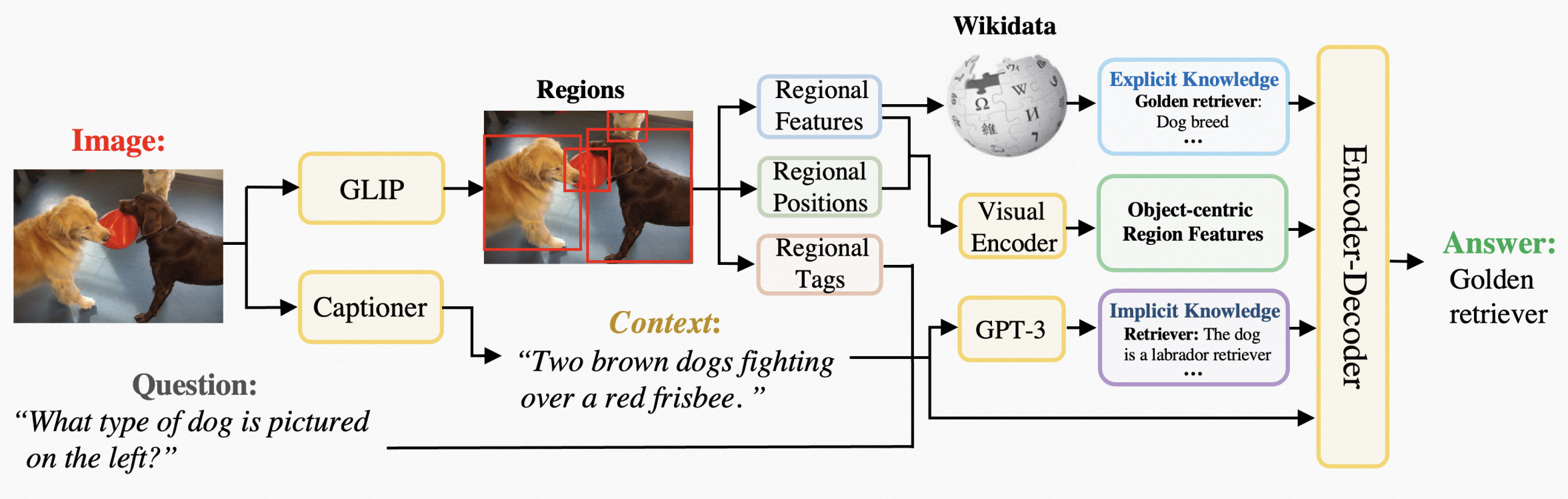
整体来说首先搜集了四种信息:

region视觉信息,box信息描述方位,和box的tag信息,以及caption用于描述物体的关系(感觉很有道理这个caption)。
除了正常的kb知识库Q,本文为region区域也建立了知识库,具体做法为:
(1)reformat原始的知识库,构建成实体和描述

(2)检索方式类似于正常的kb知识库
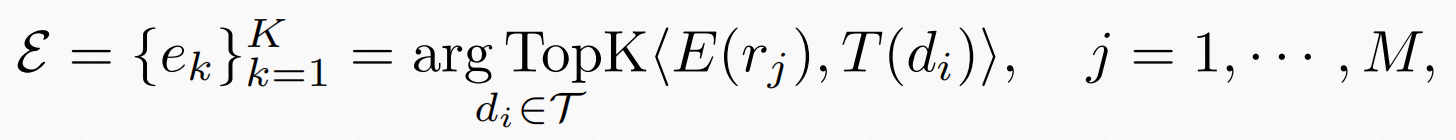
2.5.MultiInstruct
在这项工作中,作者介绍了多指令,第一个由多模态指令调整基准数据集组成的多模态指令调整基准数据集,模式任务涵盖11个大类别。每个任务至少设计了5000个来自现有开源数据集的实例(输入输出对)和5个专家编写的指令。文中还设计了一个新的评估度量-敏感度,以评估模型对各种指令的敏感性。
Introduction
每条实例被组织成统一的序列到序列格式,其中输入文本、图像、指令和边界框在相同的标记空间中表示。

MultiInstruct
2.6.MiniGPT-4
本文认为gpt4得益于使用了更先进的语言模型,本文提出了MiniGPT-4,它使用一个投影层将一个冻结的视觉编码器与一个冻结的LLM(Vicuna)对齐。整个模型只用了大约500万对图像-文本对和额外的3500个精选的高质量对进行投影层的训练。
Introduction
本文主要认为gpt4的超强能力都源于一个强大的LLM,文本端是Vicuna视觉端是ViT-G/14和Q-Former。MiniGPT-4只添加了一个投影层,以将编码的视觉特征与Vicuna语言模型对齐,并冻结了所有其他的视觉和语言组件。
MiniGPT-4先用基本的图文对数据来train,使得文本图像端能对齐,然后用3500高质量pairs+自定模版来激发能力。
本文证明了:
(1)我们的研究表明,通过将视觉特征与先进的大型语言模型Vicuna相结合,我们可以实现突发的视觉语言能力。我们证明了我们的MiniGPT-4可以推进 与GPT-4演示中展示的能力相似。
(2)仅仅训练一个投影层就可以有效地进行训练 y将视觉特征与大型语言模型对齐。
(3)公开数据质量低,不足以对齐,得加入一些超高质量数据。
Framework
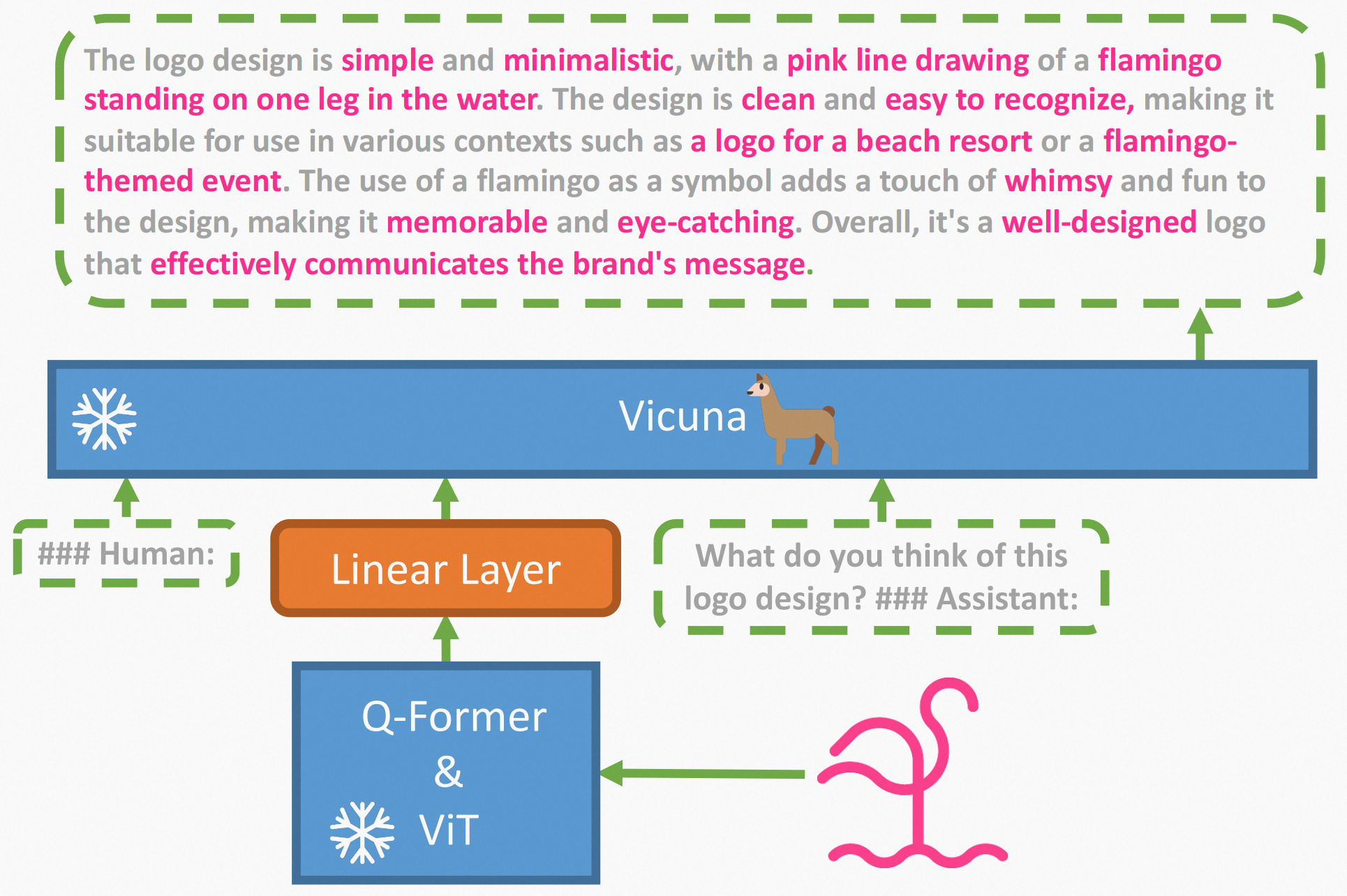
本文说图文对预训练(这里的预训练只训练mlp),minigpt4能有能力但是语言不完整,常常生成碎片化的重复的东西。我们还注意到,在GPT-3中也面临着类似的问题。尽管在广泛的语言数据集上进行了预训练,GPT-3仍然不能直接生成与用户的意图一致的语言输出,需要微调解决。
第一阶段:
图文对预训练,SBU和LAION
第二阶段:
用高质量数据集来微调,高质量图文对主要体现为文本的高质量

它采用prompt一次判断句子长度是否超出80tokens,如果超出则保存,否则加一个下面的prompt,把两次的句子连起来,这样得到5000个图文对。

然后又人工筛选出里面质量最高的3500条。
然后根据格式:
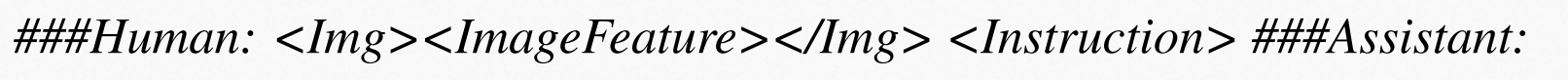
进行二阶段训练。
Limitations
感知能力不足。MiniGPT-4的视觉感知仍然有限。它可能难以从图像中识别详细的文本信息,并区分空间定位。可能源于以下几个因素:
1)缺乏足够的对齐图像-文本数据,其中包含足够的信息,如空间定位和光学字符注释。这个问题可以通过对更一致和丰富的数据的训练来缓解
2)还有就是说整体匹配的视觉端就像Q-fomer和clip的vit这种会丢失很多视觉信息
3)只训练一个投影层可能无法提供足够的能力来学习广泛的视觉-文本对齐