多模态模型评测调研
1.纯文本
(1)benchmark形式评测
Holistic Evaluation of Language Models(HELM)一文对大语言模型整体评估
HELM是一种语言模型整体评估方法,旨在提高语言模型的透明度和可靠性。该方法将潜在场景和感兴趣的指标进行分类,并采用多指标方法对各种核心场景进行测量,以确保模型和指标之间的折衷关系得到清晰的暴露。同时,该方法对30个知名的语言模型进行了大规模评估,覆盖了所有42个场景,并展示了25个重要的发现。为了完全透明,HELM公开了所有原始模型输入提示和输出生成,并提供了一个通用的模块化工具包,方便添加新的场景、模型、指标和提示策略。
但是,整体评估语言模型意味着什么呢?语言模型是通用的文本接口,可以应用于广泛的场景。对于每个场景,我们可能有一套广泛的期望:模型应该准确、稳健、公平、高效等。事实上,这些期望的相对重要性通常不仅取决于个人的观点和价值观,还取决于场景本身(例如,在移动应用中,推理效率可能更为重要)。
Academic Benchmarks
子任务:
Bias: Winogender、CrowS Pairs、Real Toxicity
QA:Truthful QA、DROP、QuAC、SquadV2、Hellaswag
Summarization:TLDR Summarization、CNN/DM Summarization
Translation:WMT Fr → En 15
Entailment:RTE
Sentiment:SST
Synthetic:WSC (Winograd Schema Challenge
评测方法:
Automatic Evaluations(ACC/F1/BLEU/Rouge)
(2)用专门的评测模型评测
这个想法挺好的,因为其实benchmark的评测不太全面,有些死板,很多开放域问答并不能很好的评测。个人在做相关研究和评测我们的模型的时候发现一个自动化评测的pipeline是非常有必要的。
PandaLM: Reproducible and Automated Language Model Assessment是一个专门用于评测的模型
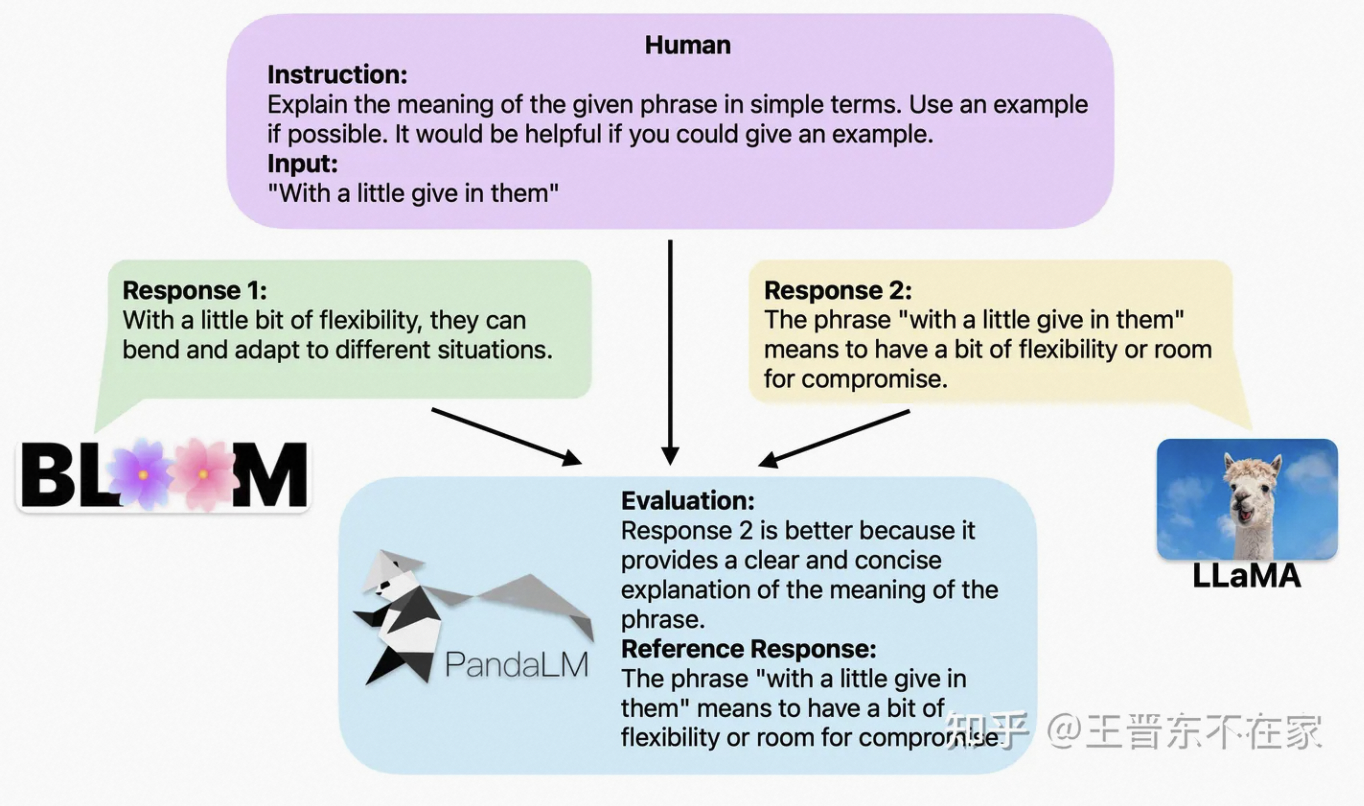
文章指出,现在大家评估大模型的方法主要有两个:
- 调用OpenAI的API接口;
- 雇佣专家进行人工标注。 然而,发送数据给OpenAI可能会像三星员工泄露代码一样造成数据泄露问题;雇佣专家标注大量数据又十分费时费力且昂贵。
PandaLM是个专门用于纯文本评测的大模型,文章称:为了验证PandaLM的大模型评估能力,我们构建了一个多样化的包含约1,000个样本的人工标注测试集,其上下文和标签均由人类创建。「在我们的测试数据集上,PandaLM-7B在准确度达到了ChatGPT(gpt-3.5-turbo)的94%的水平」。