在开始之前先学习一下低成本微调大模型的方案:LoRA:LoRA: Low-Rank Adaptation of Large Language Models
1.LoRA的原理
LoRA是一种以极低资源微调大模型的方法。
1.1大模型微调的困境
随着模型规模的不断扩大,模型会”涌现”出各种能力。特别是对大语言模型(LLM)来说,随着规模的扩大其在zero-shot、常识推理等能力上会有大幅度的提高。相比于规模较小的模型,大模型的微调成本和部署成本都非常高。例如,GPT-3 175B模型微调需要1.2TB的显存。此外,若针对不同下游任务微调多个模型,那么就需要为每个下游任务保存一份模型权重,成本非常高。在某些场景下,甚至可能需要针对不同的用户微调不同的模型,那么模型微调和部署的成本将不可接受。
1.2LoRA之前的方法
在LoRA方法提出之前,也有很多方法尝试解决大模型微调困境的方法。其中有两个主要的方向:(1) 添加adapter层;(2) 由于某种形式的输入层激活。但是这两种方法都有局限性:
(1)Adapter:
缺点:Adapter层会引入推理时延
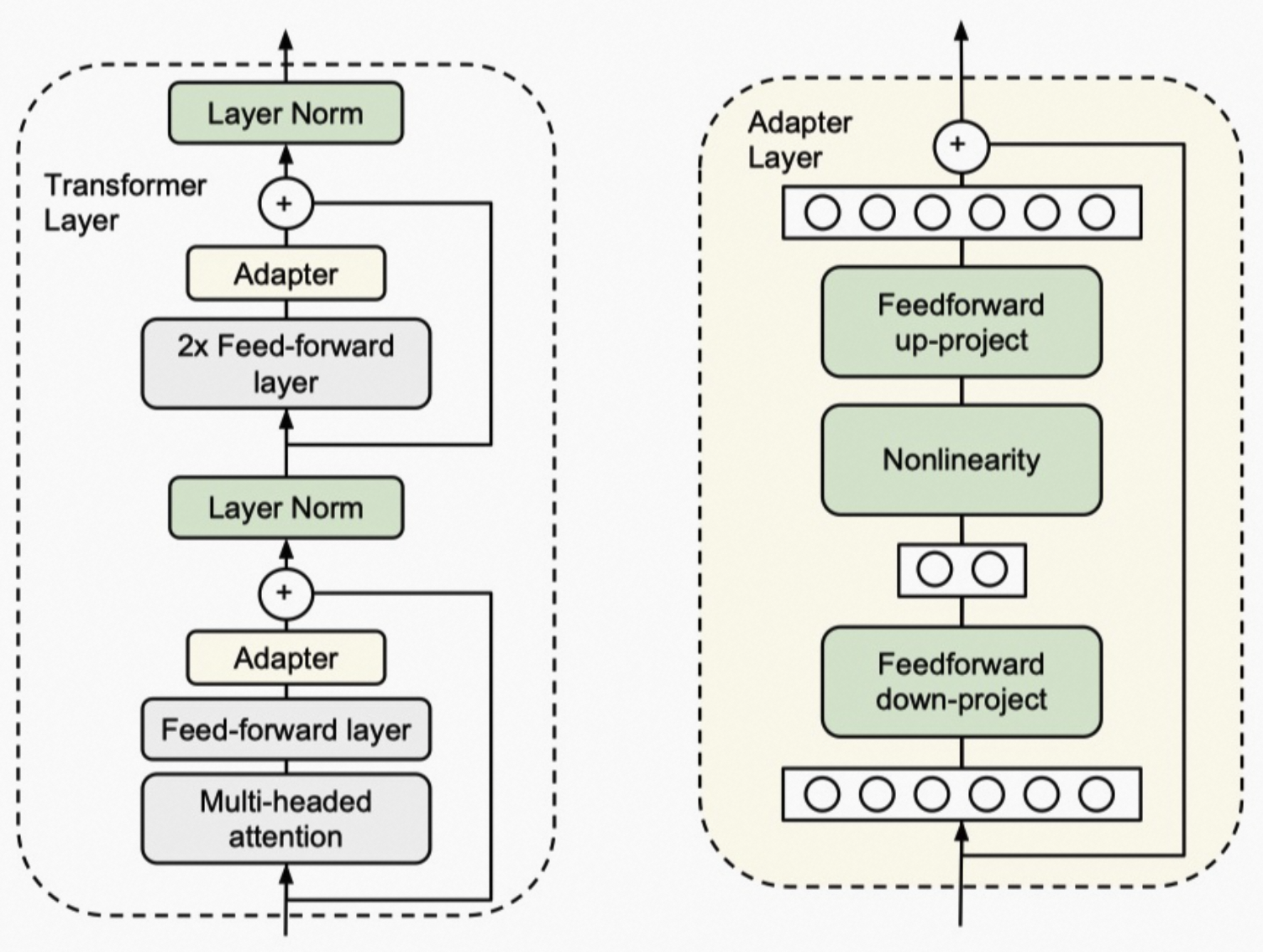
简单来说,adapter就是固定原有的参数,并添加一些额外参数用于微调。上图中会在原始的transformer block中添加2个adapter,一个在多头注意力后面,另一个这是FFN后面。
显然,adapter会在模型中添加额外的层,这些层会导致大模型在推理时需要更多的GPU通信,而且也会约束模型并行。这些问题都将导致模型推理变慢。
(2)prefix-tuning:

prefix-tuning方法是受语言模型in-context learning能力的启发,只要有合适的上下文则语言模型可以很好的解决自然语言任务。但是,针对特定的任务找到离散token的前缀需要花费很长时间,prefix-tuning提出使用连续的virtual token embedding来替换离散token。
具体来说,对于transformer中的每一层,都在句子表征前面插入可训练的virtual token embedding。对于自回归模型(GPT系列),在句子前添加连续前缀,即 z=[PREFIX;x;y] 。对于Encoder-Decoder模型(T5),则在Ecoder和Decoder前都添加连续前缀 z=[PREFIX;x|PREFIX′;y] 。添加前缀的过程如上图所示。
虽然,prefix-tuning并没有添加太多的额外参数。但是,prefix-tuning难以优化,且会减少下游任务的序列长度。
1.3问题的正式表述
术语与约定。由于LoRA原理的介绍,会使用Transformer架构。因此,这里先给出一些术语约定。一个Transformer层的输入和输出维度尺寸为:
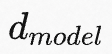
,使用 Wq、Wk、Wv和Wo表示自注意力模块中的query/key/value/output投影矩阵。 W或W0 表示预训练模型的权重矩阵, ΔW 表示模型在适配过程中的梯度更新。r来表示LoRA模块的秩。使用Adam作为模型优化器,Transformer MLP前馈层的维度为 :
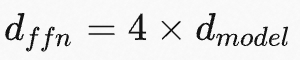 。
。
问题表述。LoRA虽然与训练目标无关,这里还是以语言建模为例。假设给定一个预训练的自回归语言模型 PΦsub>(y|x) , Φ 是模型参数。目标是使该语言模型适应下游的摘要、机器阅读理解等任务。每个下游任务都有context-target样本对组成的训练集: z={(xi,yi)}i=1,…,N,其中 xi 和 yi 都是token序列。例如,对于摘要任务, xi 是文章内容,yi是摘要。
在完整微调的过程中,模型使用预训练好的权重 Φ0 来初始化模型,然后通过最大化条件语言模型来更新参数 Φ0+ΔΦ :
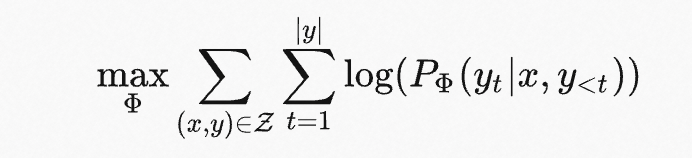
完整微调的主要缺点:对于每个下游任务,都需要学习不同的参数更新 ΔΦ ,其中维度 |ΔΦ|=| Φ0 | 。因此,如果预训练模型很大,存储和部署许多独立的微调模型实例非常有挑战。
LoRA为了更加的参数高效,使用相对非常小的参数 Θ 来表示任务相关的参数增量 ΔΦ=ΔΦ(Θ) ,其中 |Θ|≪| Φ0 | 。寻找 ΔΦ 的任务就变成对 Θ 的优化:
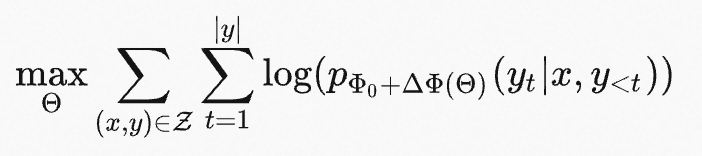
LoRA将会使用低秩表示来编码 ΔΦ ,同时实现计算高效和存储高效。当预训练模型是175B GPT-3,可训练参数 |Θ| 可以小至 |Φ0 | 的 0.01% 。
1.4LoRA
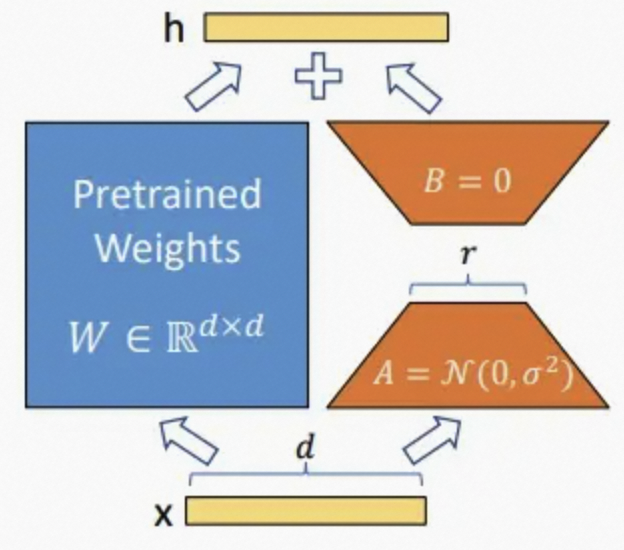
通常,神经网络中会包含许多进行矩阵乘法的稠密层,这些层通常是满秩的。在模型适配下游任务的过程中,权重更新也应该具有低的“内在秩”。对于预训练权重矩阵 W0∈Rd×k ,可以通过低秩分解来表示其更新 ,W0+ΔW=W0+BA,B∈Rd×r, A∈Rr×k 且秩 r≪min(d,k) 。在训练过程中, W0被冻结且不接受梯度更新,A和B则是可训练参数。注意, W0和 ΔW=BA 都会乘以相同的输入。对于h=W0x ,前向传播变为:
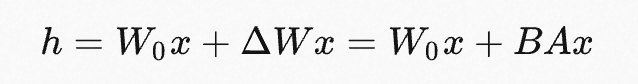
对矩阵 A 使用随机高斯初始化,对矩阵 B 使用0进行初始化,因此 ΔW=BA 在训练的开始为0。使用 a/r 来缩放 ΔWx 。当使用Adam优化时,经过适当的缩放初始化,调优a与调优学习率大致相同。
当进行部署时,以显式的计算和存储 W=W0+BA ,并正常执行推理。 W0 和BA都是Rd×k。当需要转换至另一个下游任务,可以通过减去 BA来恢复W0 ,然后添加不同的 B′A′ 。至关重要的是,这保证不会引人任何额外的推理时延。
2.BLOOM学习:一个176B参数且可开放获取的多语言模型
BigScience Large Open-science Open-access Multilingual Language Model(BLOOM)。BLOOM是在46种自然语言和13种编程语言上训练的1760亿参数语言模型,其是由数百名研究人员合作开发和发布的。
2.1训练数据
多任务提示微调(也称为instruction tuning)涉及到对预训练语言模型的微调,微调的数据集由通过自然语言提示构成的大量不同任务组成。T0证明了在多任务混合的prompted数据集上微调的模型具有强大的zero-shot泛化能力。此外,T0优于那些数量级大但是没有经过这种微调的语言模型。受这些结果启发,我们探索了使用现有自然语言数据集来进行多任务prompted微调。

T0是在Public Pool of Prompt(P3)子集上进行训练的,其是一个各种现有的、开源的应用自然语言数据集的prompt集合。该prompt集合是通过BigScience合作者参与的一系列黑客马拉松创建的,其中黑客马拉松参与者为170+数据集编写了2000+的prompt。P3中的数据集覆盖了各种自然语言任务,包括情感分析、问答、自然语言推理,并且排除了有害的内容或者非自然语言。PromptSource,一个开源工具包促进了自然语言prompt的创建、共享和使用。
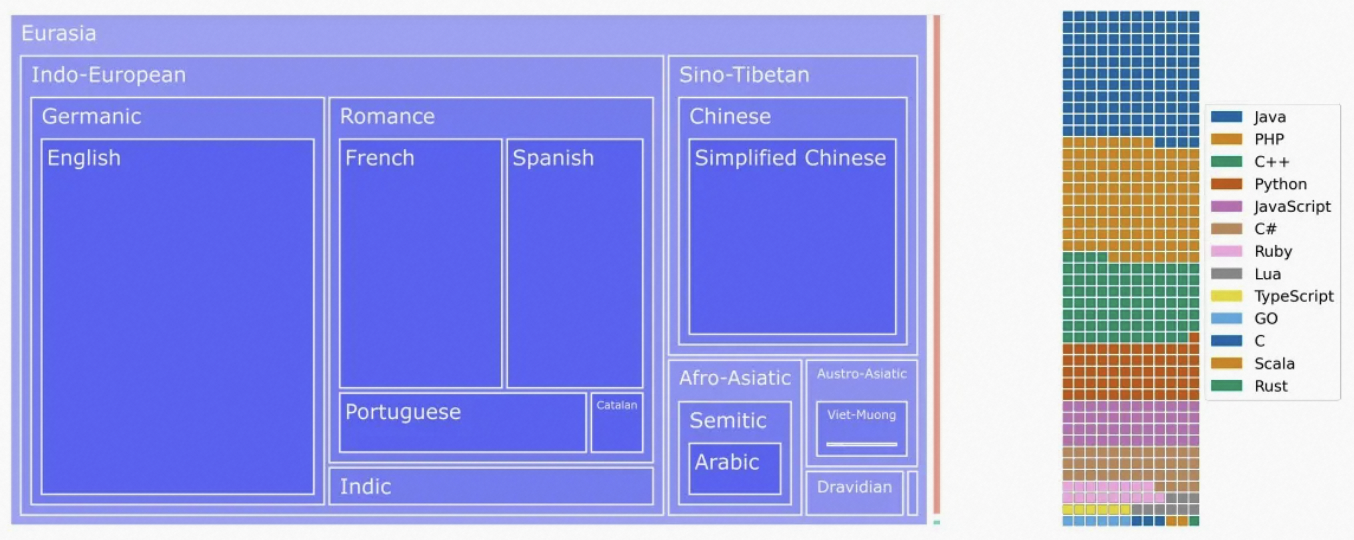
对BLOOM预训练之后,我们应用相同的大规模多任务微调,使BLOOM具有多语言zero-shot任务泛化能力。我们称得到的模型为BLOOMZ。为了训练BLOOMZ,我们扩展了P3来包含非英语中新数据集和新任务,例如翻译。这产生了xP3,它是83个数据集的提升集合,覆盖46种语言和16中任务。正如上图所述,xP3反映了ROOTS的语言分布。xP3中的任务包含跨语言和单语言。我们使用PromptSource来收集这些prompts,为prompt添加额外的元数据,例如输入和目标语言。为了研究多语言prompt的重要性,我们还将xP3中的英语提示用机器翻译为相应的数据集语言,来生成一个称为xP3mt的集合。
3.DeepSpeed使用指南
3.1核心思想(TLDR)
GPU不够,CPU来凑,例如:我们只有一张10G的gpu,那么我们很可能需要借助80G的CPU,才能训练一个大模型。
具体点说,DeepSpeed将当前时刻,训练模型用不到的参数,缓存到CPU中,等到要用到了,再从CPU挪到GPU。这里的“参数”,不仅指的是模型参数,还指optimizer、梯度等。
越多的参数挪到CPU上,GPU的负担就越小;但随之的代价就是,更为频繁的CPU,GPU交互,极大增加了训练推理的时间开销。因此,DeepSpeed使用的一个核心要义是,时间开销和显存占用的权衡。
3.2如何安装
直接pip安装:
1 | pip install deepspeed |
官方更推荐的是用仓库本地编译安装,能够更加适配你的本地硬件环境:
1 | git clone https://github.com/microsoft/DeepSpeed/ |
另外,HuggingFace提供了对DeepSpeed的友好集成,DeepSpeed使用所需要的很多参数,都可以由Transformer的Trainer来自动指定。可以说,DeepSpeed在HuggingFace Transformer上的使用,会更为便捷(当然,DeepSpeed也可以独立使用,并不依赖于Transformer)。
作为Transformer的附属包安装:
1 | pip install transformers[deepspeed] |
3.3如何使用
使用DeepSpeed之后,你的命令行会像下面:
1 | deepspeed --master_port 29500 --num_gpus=2 run_s2s.py \ |
==–master_port==:端口号。最好显示指定,默认为29500,可能会被占用(i.e., 跑了多个DeepSpeed进程)。
==–num_gpus==: GPU数目,默认会使用当前所见的所有GPU。
==–deepspeed==: 提供的config文件,用来指定许多DeepSpeed的重要参数。
使用DeepSpeed的一个核心要点,就在于写一个==config==文件(可以是.json,也可以是类json格式的配置文件),在这个配置文件中,你可以指定你想要的参数,例如,权衡时间和显存 (前文所提到的,这是一个很重要的权衡)。因此,上面几个参数里,最重要的便是==–deepspeed==,即你提供的config文件,即==ZeRO==。这也是本文接下来要重点介绍的。
3.3.1ZeRO
Zero Redundancy Optimizer (ZeRO)是DeepSpeed的workhorse. 用户可以提供不同的ZeRO config文件,来实现DeepSpeed的不同功能特性。
一句话总结: partitioning instead of replicating,划分而不是复制。
即,传统的深度学习,模型训练并行,是将模型参数复制多份到多张GPU上,只将数据拆分(如,torch的Dataparallel),这样就会有大量的显存冗余浪费。而ZeRO就是为了消除这种冗余,提高对memory的利用率。注意,这里的“memory”不仅指多张GPU memory,还包括CPU。而ZeRO的实现方法,就是把参数占用,逻辑上分成三种类型。将这些类型的参数划分:
optimizer states:即优化器的参数状态。例如,Adam的动量参数。gradients:梯度缓存,对应于optimizer。parameters:模型参数。
对应的,DeepSpeed的ZeRO config文件就可以分为如下几类:
ZeRO Stage 1: 划分optimizer states。优化器参数被划分到多个memory上,每个momoey上的进程只负责更新它自己那部分参数。ZeRO Stage 2: 划分gradient。每个memory,只保留它分配到的optimizer state所对应的梯度。这很合理,因为梯度和optimizer是紧密联系在一起的。只知道梯度,不知道optimizer state,是没有办法优化模型参数的。ZeRO Stage 3: 划分模型参数,或者说,不同的layer. ZeRO-3会在forward和backward的时候,自动将模型参数分配到多个memory。
由于ZeRO-1只分配optimizer states(参数量很小),实际使用的时候,我们一般只会考虑ZeRO-2和ZeRO-3。
接下来介绍stage 2和3的常用config文件。
3.3.2ZeRO Stage 2
一个常用的ZeRO-stage-2的config文件:
1 | { |
- 有关于
offload
上述参数中,最重要的一个就是"offload_optimizer"。如上述所示,我们将其”device“设置成了cpu,DeepSpeed就会按照之前提到过的ZeRO操作,在训练过程中,将优化器状态分配到cpu上。从而降低单张GPU的memory占用。
- 有关于
overlap_comm
另外一个需要提到的参数是overlap_comm。简单地理解,它控制着多个memory上进程之间通信的buffer的大小。这个值越大,进程之间通信越快,模型训练速度也会提升,但相应的显存占用也会变大;反之亦然。
因此,overlap_comm也是一个需要进行一定权衡的参数。
- 有关于
auto
我们可以发现,上述大量参数被设置为auto。由于DeepSpeed目前已经被集成到了HuggingFace Transformer框架。而DeepSpeed的很多参数,和Transformer的Trainer参数设置是一模一样的,例如,"optimizer","scheduler"。因此,官方推荐将很多常用的模型训练参数,设置为auto,在使用Trainer进行训练的时候,这些值都会自动更新为Trainer中的设置,或者帮你自动计算。
当然,你也可以自己设置,但一定要确保和Trainer中的设置一样。因为,如果设置错误,DeepSpeed还是会正常运行,不会立即报错。
3.3.3ZeRO Stage 3
1 | { |
- 有关于
“offload_param”
可以看到,除了和stage2一样,有offload_optimizer参数之外,stage3还有一个offload_param参数。即,将模型参数进行划分。
- stage-3相关的其他参数
下面这些参数是stage-3-specific的:
1 | "sub_group_size": 1e9, |
一样的道理,这些值很多都可以用来控制stage-3的显存占用和训练效率(e.g.,sub_group_size);同时,有一些参数也可以设置为auto,让Trainer去决定值(e.g., reduce_bucket_size,stage3_prefetch_bucket_size,stage3_param_persistence_threshold).
3.3.4ZeRO Infinity
除了stage2和3之外,这里简单介绍一下ZeRO-Infinity。
ZeRO-Infinity可以看成是stage-3的进阶版本,需要依赖于NVMe的支持。他可以offload所有模型参数状态到CPU以及NVMe上。得益于NMVe协议,除了使用CPU内存之外,ZeRO可以额外利用SSD(固态),从而极大地节约了memory开销,加速了通信速度。
建议:
在使用DeepSpeed之前,先使用上述代码,大概估计一下显存消耗,决定使用的GPU数目,以及ZeRO-stage。
原则是,能直接多卡训练,就不要用ZeRO;能用ZeRO-2就不要用ZeRO-3.